一. 发现问题
最近新版本上线,公司内部的几台iphone测试机测试都一切正常,但是外网用户却频频反馈崩溃。
在友盟上看了错误率统计,曲线如下:
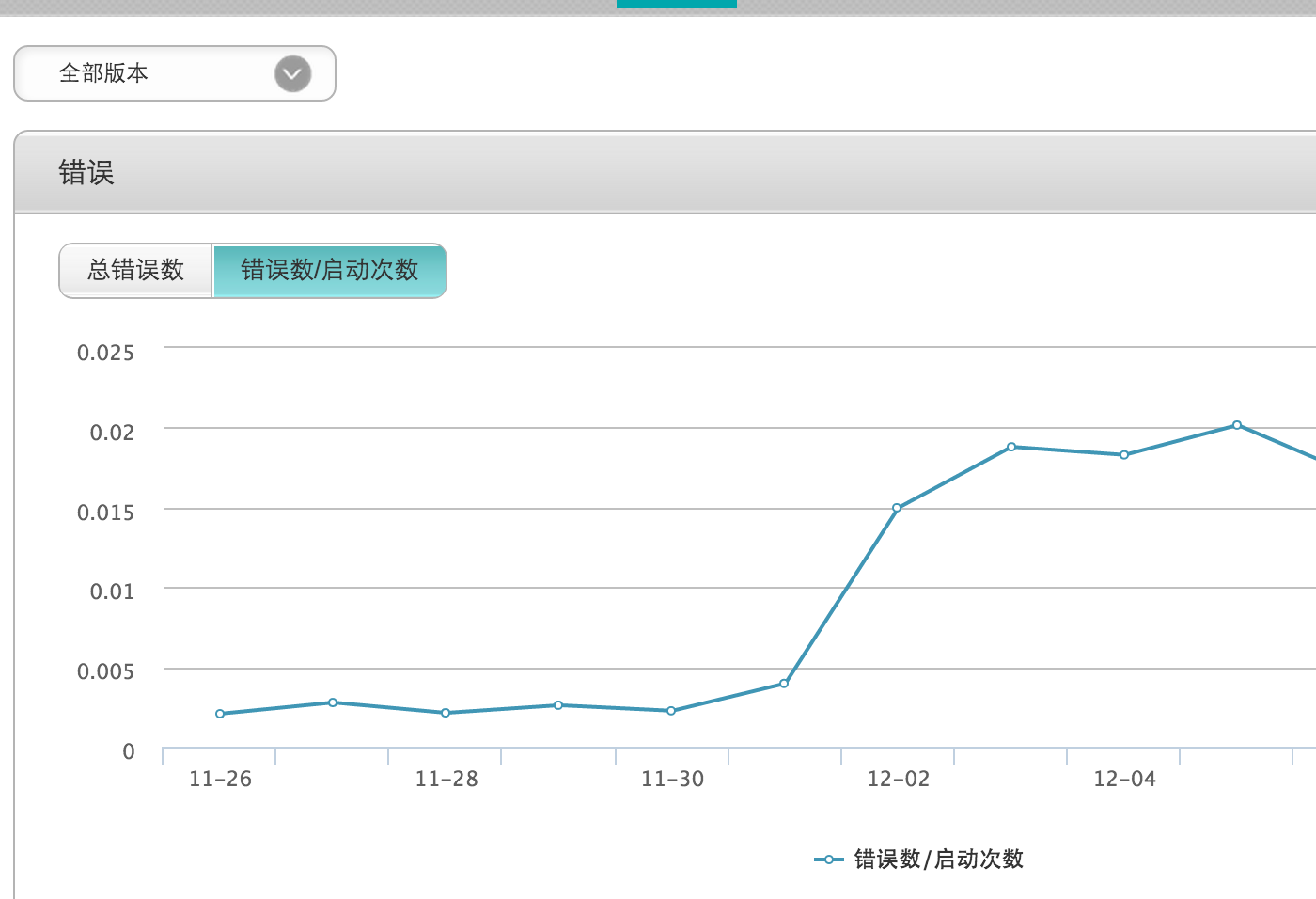
可以看出,错误率确实有了很大的上浮。基本可以确认一定是出问题了。
二. 还原崩溃现场
我们游戏用得cocos2dx-lua,既然是崩溃,那就一定是到了c++端了,我们点击友盟上数量最多的那个看一下:
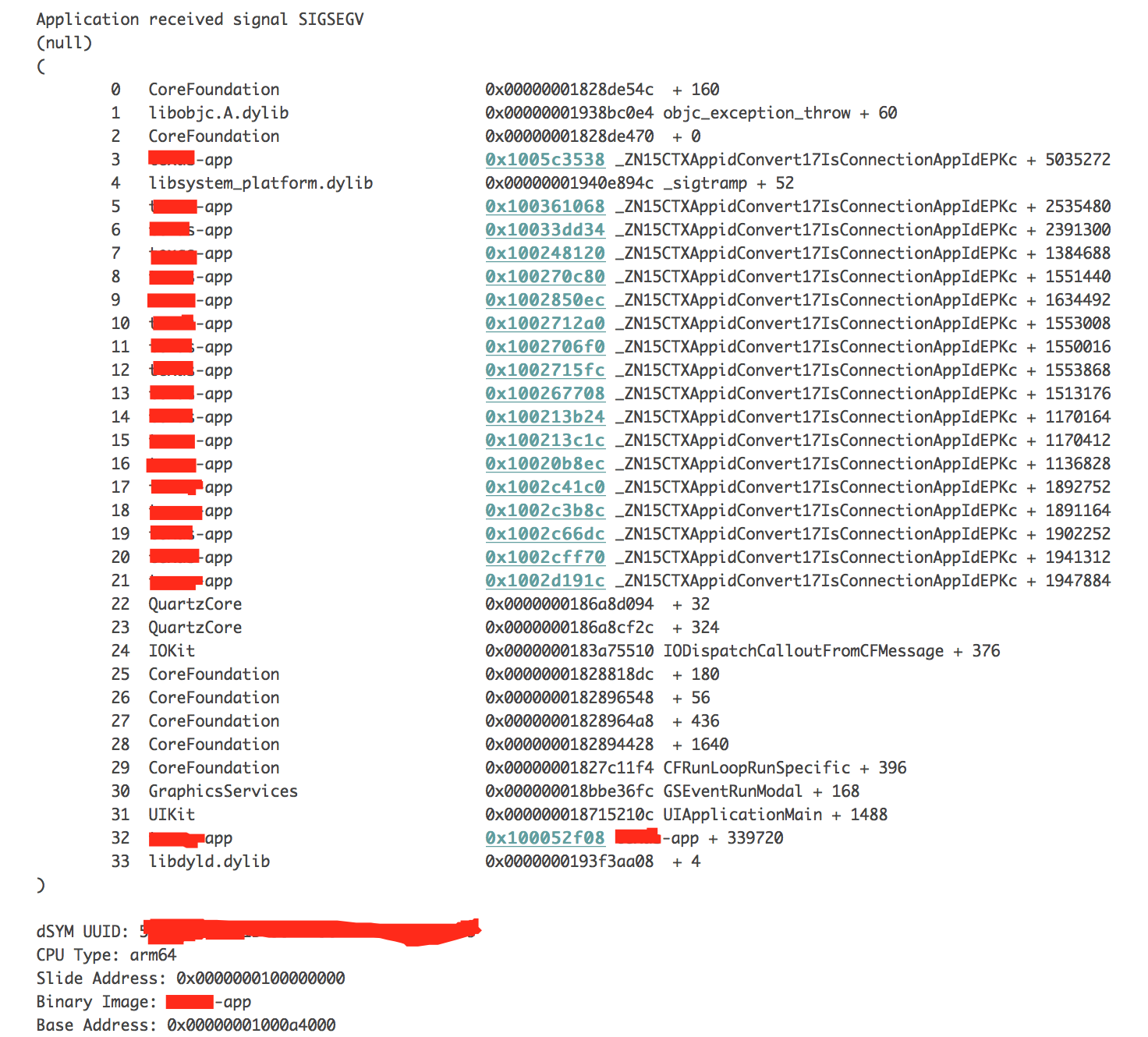
到了这里,遇到了第一个难点,因为按照友盟文档,使用他的错误dump工具是无效的,一旦看不到具体的错误内容,基本就无法继续了。
(而因为这个问题,发现有人推荐bugly,打算在下一个版本里面试用一下,再给大家反馈)
既然友盟提供的工具不行,我们就得像别的办法,起码现在错误的原始内容是有了,只是要想办法还原出来而已。
仔细研究了一下,友盟其实也是使用了mac原本就提供的工具来做了二次封装,那不如直接用原生的工具了。
具体方法如下:
-
找到当时出包得那个archive文件,显示包文件,在其中找到如下两个文件放到同一目录:
xxx.app xxx.app.dSYM其中 xxx.app.dSYM 即为符号表文件。
-
查看其对应的UUID,一定要与crash log的UUID一致
$ dwarfdump --uuid xxx.app/xxx UUID: 934F5569-B8C7-3F7D-8E9F-919D7473A3C4 (armv7) xxx.app/xxx UUID: 54875A74-A91B-382E-8CEB-DFD26C812F39 (arm64) xxx.app/xxx $ dwarfdump --uuid xxx.app.dSYM UUID: 934F5569-B8C7-3F7D-8E9F-919D7473A3C4 (armv7) xxx.app.dSYM/Contents/Resources/DWARF/xxx UUID: 54875A74-A91B-382E-8CEB-DFD26C812F39 (arm64) xxx.app.dSYM/Contents/Resources/DWARF/xxx -
crash对应的函数定位:
$ atos -arch arm64 -o xxx.app.dSYM/Contents/Resources/DWARF/xxx 0x10033dd34 cocos2d::Sprite::setTexture(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&) (in xxx) + 100
按照这种方法,最终定位在代码崩溃在了 CCSprite::setTexture(path) 这个函数里面,当传入path文件不存在或者不合法时,cocos代码没有做检查:
void Sprite::setTexture(const std::string &filename)
{
Texture2D *texture = Director::getInstance()->getTextureCache()->addImage(filename);
setTexture(texture);
Rect rect = Rect::ZERO;
rect.size = texture->getContentSize();
setTextureRect(rect);
}
其中的texture并没有检查是否为null,就执行了后面的getContentSize。
同样的ImageView在调用loadTexture时,在内部也是调用了setTexture(path)。
三. 定位崩溃代码
知道了C++端的崩溃代码,不代表就知道了lua端的调用,因为我们的业务逻辑都是用lua的。
现在面临了如下几个问题:
- 定位lua的崩溃代码。因为lua端调用
setTexture的地方太多太多了. - 无法确认问题是否解决。由于我们公司的机器都无法重现,所以即时改了代码也不知道到底有没有解决。
第一个问题和第二个问题是循环在面对的,因为无法知道确切的崩溃位置,所以我们只能靠猜测先去改,但是改完了怎么才能知道已经改好了呢?
所以为了解决用户测试的问题,我们造出了对以后定位问题以及发布新版本有巨大帮助的系统:定向热更新。
即,仅针对固定几个IP,做代码热更新的功能。如果没有问题,再全部更新到外网。
这个想法其实就是来源于当年在腾讯的灰度发布。
而之所以选择使用IP,我们客户端进入游戏分为两步:
- 拉取服务器信息,包括gateway的ip和端口,大版本更新的状态,热更新的状态等等,这个时候是还没有用户ID的
- 登陆gateway。
所以,目前能想到的最好的方式就是通过IP做灰度。
那么接着往下说,灰度了几次之后,用户那边还是说崩溃。
感觉问题定位的有点散。
这个时候,我打算让用户配合我们录一下崩溃的视频,我们看一下能不能看出什么东西,后面解决问题后会给用户奖励。
也非常感谢我们这些忠诚的用户,有两位用户给我们发送了视频。
用户也很细心,都是崩溃一次之后,又点击了一次应用,然后又崩溃一次。
在仔细的对比和观察了视频之后,我发现了一个很奇怪的问题,就是第一次崩溃后,第二次打开时,对于本地数据最大的区别就是一个用户的头像从没有头像到显示头像了。
那也就是说,基本可以确定用户在第一次崩溃的时候,头像已经下载下来了,但是没有渲染出来,所以之后再打开的,头像会立即渲染出来。
那么,问题基本就可以确认是在头像下载完成后的渲染上了。
而这次我们新版本确实重写了整个头像下载类。
为了验证整个想法,我把游戏内头像的下载整个关闭掉,定向给用户更新,结果用户反馈,果然不崩溃了。
问题确认是头像下载之后的渲染了。
再结合之前看到的c++端setTexture崩溃,我们很轻易的找到了那行seTexture代码。
这行代码看起来正常的不能再正常,而且还在前面用io.exists(path)判断了路径是否存在。虽然我自己也不愿意相信,但是种种证据都指向了这里。
原来代码如下:
node:setTexture(path)
所以我代码改成这样,试了一下:
if not io.exists(path) then return end
local fileTexture = cc.Sprite:create(path):getTexture()
-- cocos底层不够健壮,如果texture为null导致崩溃
if not fileTexture then
loge("getTexture fail. path: " .. path)
return
end
node:setTexture(fileTexture)
定向更新之后,果然没问题了。
再去看看cocos2dx3.2的内部到底怎么写的:
void Sprite::setTexture(const std::string &filename)
{
Texture2D *texture = Director::getInstance()->getTextureCache()->addImage(filename);
setTexture(texture);
Rect rect = Rect::ZERO;
rect.size = texture->getContentSize();
setTextureRect(rect);
}
果然,texture没有做是否为null的判断。
到此为止,问题已经圆满解决了,之后又改了一个同样的loadTexture的问题,然后我们的错误率曲线终于变成了正常的样子:
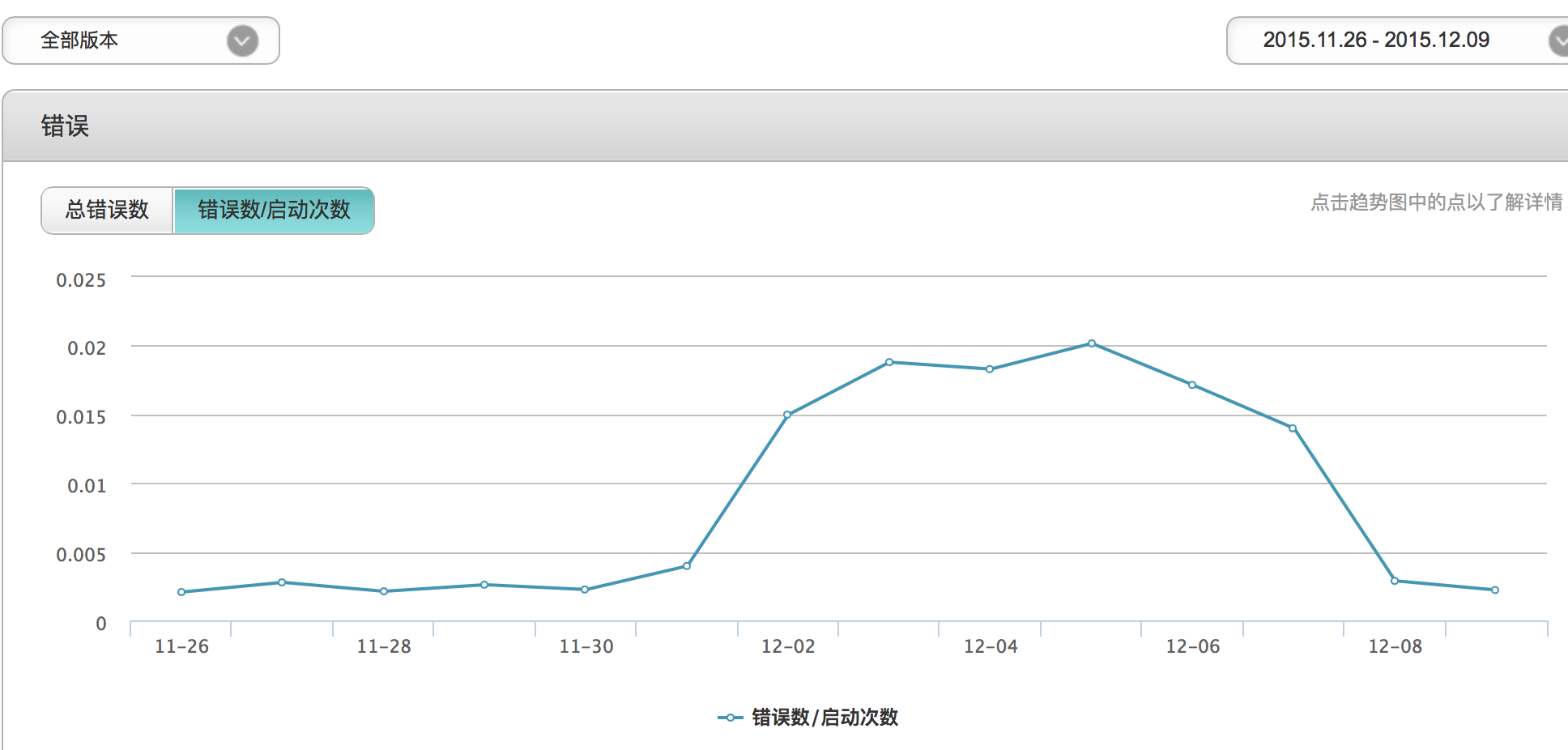
在此完整记录,希望对大家有用。
依云 on #
一路看下来,还是不知道预期存在的文件为什么会不在呢。
Reply
Dante on #
对,这个问题最终还是不知道。
暂时没有时间去深究了,还有一堆需求等着。。等以后再看。
Reply
吉米 on #
因为文件损坏了,虽然有文件名。
Reply
吉米 on #
因为图片文件损坏
Reply